



Photo by Jeremy Bishop on Unsplash
Unlocking the Power Within: A Guide on Training Language Models for Internal Data
Leveraging Your Internal Data to Train LLMs for Specific Tasks


Motivation
Artificial intelligence is in the air. I don’t think a day goes by without hearing the word “AI” or “LLM” at least once. I became curious about AI and machine learning several years ago. Somehow, the mathematical and research-driven nature of the work, which required a significant amount of dedicated time, kept me away from it for a long time. But the recent rapid development of LLMs, especially ChatGPT, has caught everyone’s attention and made AI accessible to most. LLMs become even more powerful when you make them answer your questions based on internal data that is not available on the open internet. I was blown away after seeing this capability 🤯
Idea
Let’s consider some knowledge that ChatGPT doesn’t yet know. As of today, Dec 7, 2023, ChatGPT is trained on data only up to January 31, 2022. Consequently, it’s unaware of any events or information after that date. For instance, when I asked it “Who won the Cricket World Cup in 2023?”, I received the following response:

We can make the model used by ChatGPT aware of the 2023 World Cup by feeding it the corresponding information. Think of it like this: Imagine you have a new engineering graduate joining your organization. To train them on the specifics of your project, you only need to provide them with domain and technical knowledge. There’s no need to teach them basic skills like language, writing, or reading, as they’ve already learned those. That’s exactly what GPT does. GPT stands for Generative Pre-trained Transformer. It’s already pre-trained, and we’re simply augmenting it with additional information. This approach is referred to as RAG (Retrieval Augmented Generation).
To see RAG in action, I have used Spring AI, which is currently in the experimental phase but scheduled to become generally available (GA) in early 2024.
Project Setup
You can refer demo project here.
Create a Spring boot project with
spring-boot-starter-webandspring-boot-devtoolsas initial dependencies.Since Spring AI is in experimental phase, need to add repository in pom.xml:
<repositories>
<repository>
<id>spring-snapshot</id>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
- Add the dependency for Spring AI
<dependency>
<groupId>org.springframework.experimental.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
<version>0.7.1-SNAPSHOT</version>
</dependency>
Connect with OpenAI API
For this demo, we will use the OpenAI API to interact with the model behind ChatGPT, which is GPT-3.5. GPT-3.5 is cost-effective and sufficient for our purposes. As of today, OpenAI offers a $5 free credit upon opening a new account, which is sufficient for this experiment.
Create Secret Key in OpenAI Platform portal. We will use this secret key to make OpenAI API calls from our application. Once created, copy the key.
In
application.properties, set the OpenAI secret key property:
spring.ai.openai.api-key=${OPENAI-KEY}
Here, I have created an environment variableOPENAI-KEYthat stores the actual value of the secret key.
Feed the model data about the Cricket World Cup 2023
Create a text file
cricket-worldcup-2023.txtcontaining Cricket World Cup information.Create another file
cricket-news-prompt.st, which is used to set initial context to GPT. Normally referred as System Prompt. Here, we are asking GPT to respond like a Sports News reporter :).
You're assisting with questions about a specific news as a Sports News reporter.
...
- Create a service class
CricketRagServiceto augment our internal data with user prompt.
As we delve into the details of this class, let’s first gain a high-level understanding of how RAG functions. It follows a data pipeline technique similar to ETL (Extract-Transform-Load).
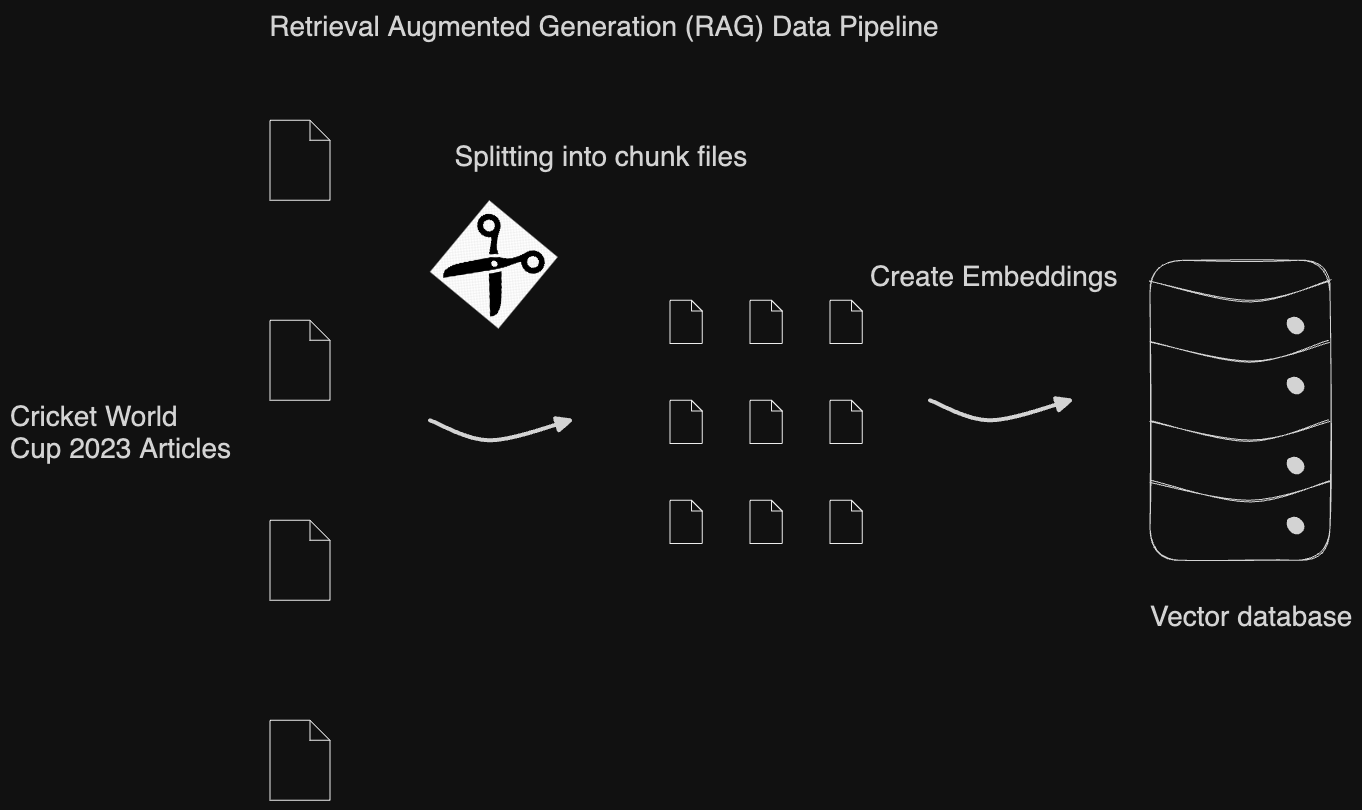
The input files are split into chunks containing plain text about the Cricket World Cup. This splitting is necessary because GPT prompts have limitations on the size of text that can be input. The resulting chunks are then encoded into binary format for storage in a vector database. These vector databases enable semantic search of the content, meaning they can assess how likely each chunk is to contain the answer to a given query.**
When a user asks a query, it is first passed through the vector database to identify the most relevant chunks of content. These identified chunks then constitute part of the “System Prompt”. Finally, the “User Prompt” is appended, such as “Who won the Cricket World Cup 2023?”
Back to code. Fortunately, Spring AI provides all the backing implementation required for RAG pipeline.
We need to just provide input plain text and associate it with a particular vector database.
In this case, we are using an in-memory vector database. In production, we should be using persistent databases.
Create AiConfig class to indicate the location of input text files.
Finally, we combine system and user prompts as a single prompt to make a call to GPT model.
public String generateResponse(String message) {
List<Document> similarDocuments =
new VectorStoreRetriever(vectorStore).retrieve(message);
UserMessage userMessage = new UserMessage(message);
Message systemMessage = getSystemMessage(similarDocuments);
Prompt prompt = new Prompt(List.of(systemMessage, userMessage));
AiResponse response = aiClient.generate(prompt);
return response.getGeneration().getText();
}
This should give us an appropriate answer, hopefully :)

Indeed, Australia won the nail-biting match.
Another one:

Yes. India defeated New Zealand to enter the finals.
Final Thoughts
Combining RAG with LLMs creates an impressive combination for integrating AI capabilities into applications. This approach may not be suitable for all use-cases, but it offers a valuable option for those who want to leverage AI with minimal effort on model training and computing costs. It’s exciting to consider the possibilities that lie ahead in the age of AI.